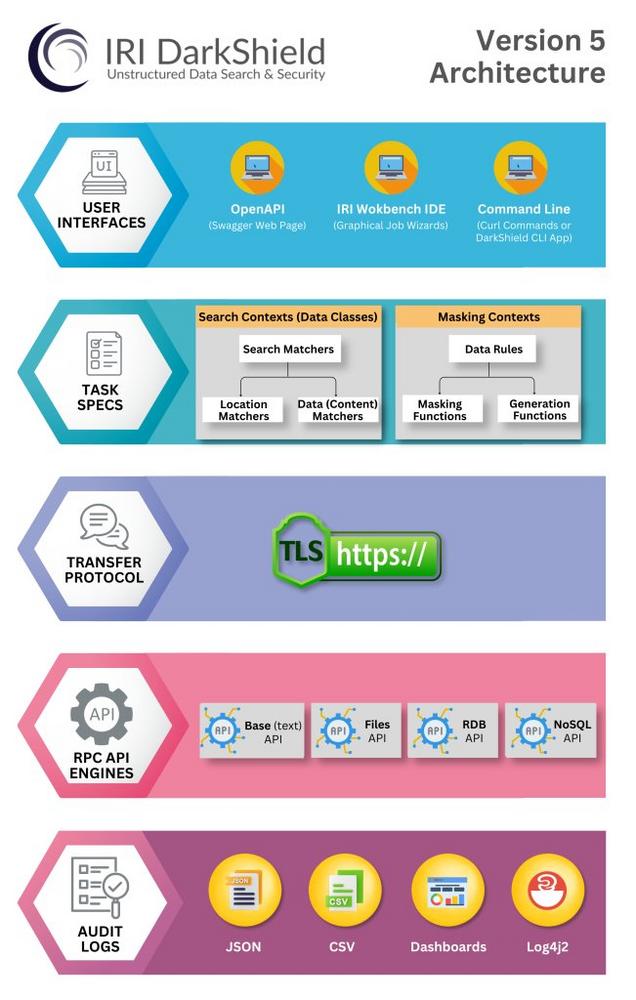
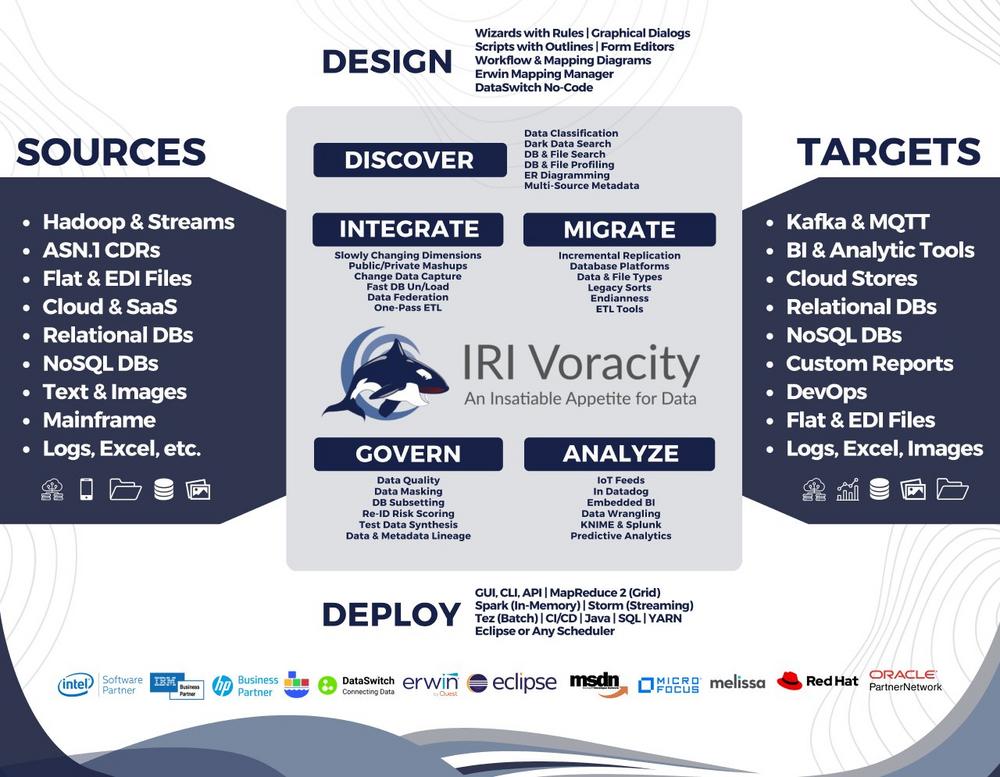
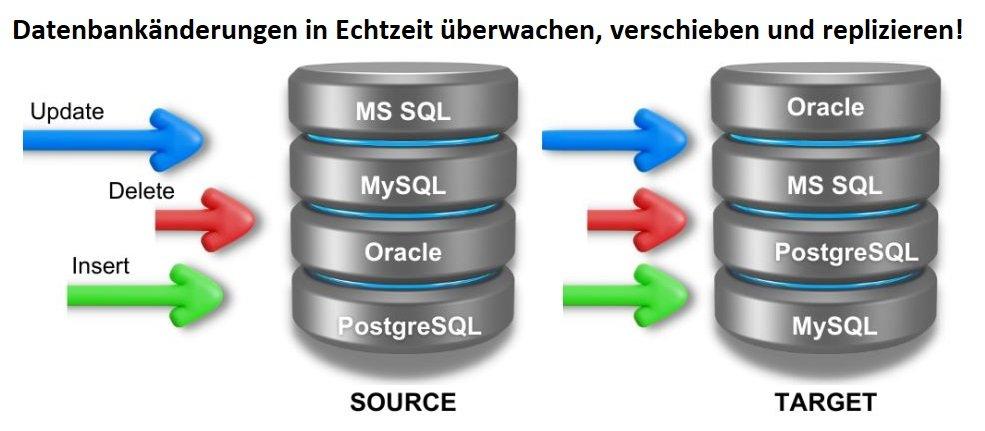
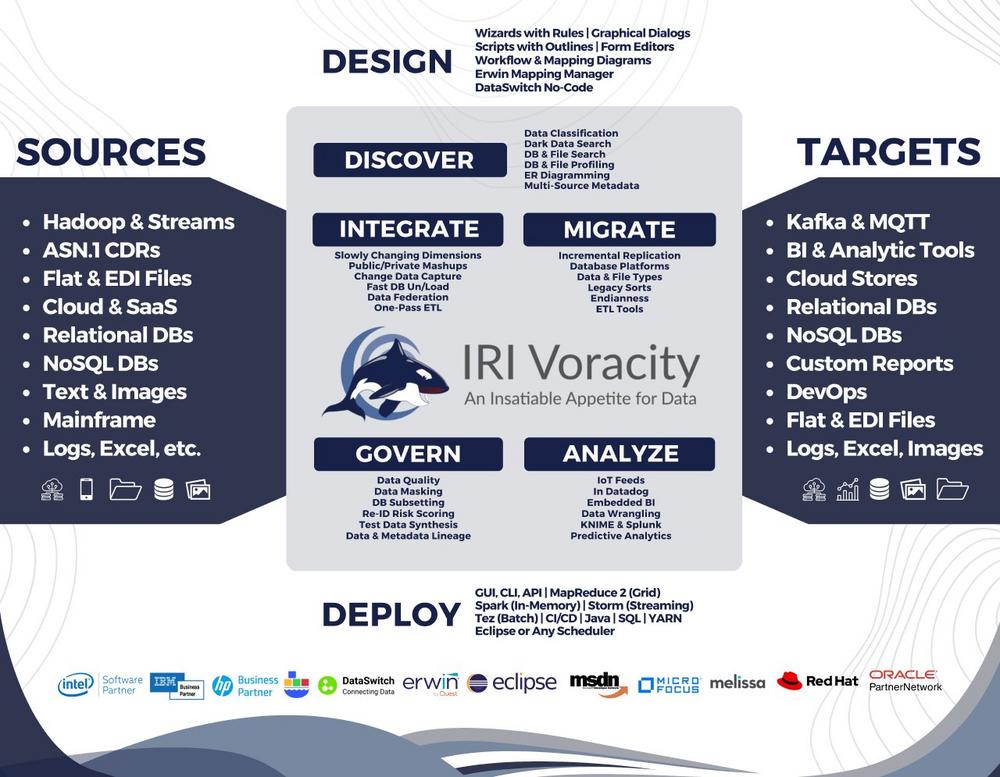
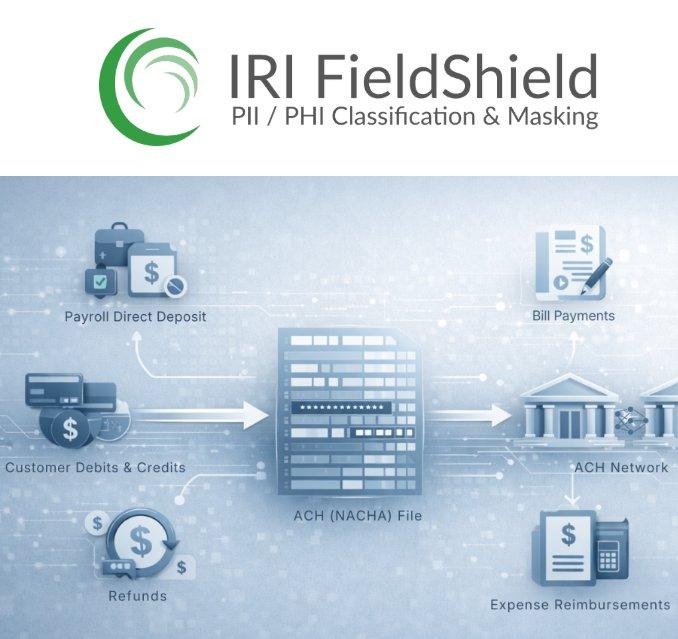
Warum Datenerkennung und Datenmaskierung für CMMC wichtig sind Viele CMMC-Kontrollen setzen voraus, dass Unternehmen: FCI und CUI zuverlässig identifizieren können – auch in strukturierten, semi-strukturierten und unstrukturierten Daten, sensible Daten in Test-, Analyse- oder Entwicklungsumgebungen minimieren, das Prinzip Least Privilege durchsetzen, nachvollziehbare und auditierbare Schutzmaßnahmen bereitstellen. Manuelle Prozesse oder isolierte Tools sind dafür meist nicht […]
continue reading